על מה הפוסט?
זהו המשך לחלק הראשון (מומלץ לקרוא או לעיין בקצרה). בחלק זה נוסיף לאפליקציה קריאה לשירות REST חיצוני ע”י שימוש בתכנות תגובתי (Reactive Programming). הפוסט נוקט בגישה פרקטית, כלומר מדגים שימוש ומספק הסבר קצר בלבד על כל תכונה/טכנולוגיה סביב השימוש בה. מי שרוצה להעמיק מוזמן לעיין בקישורים למטה.
להבנת הפוסט נדרש כמובן רקע בפיתוח בצד השרת, ואני מניח ידע בגא’ווה ובספרינג. אני משתדל להשתמש בספריות ודפוסים מוכרים מעולם הג’אווה כדי להקל על קוראים שמגיעים מרקע זה.
יש פרויקט מלווה בGithub. מי שרוצה להעמיק מוזמן להוריד את הפרויקט, לעבור לbranch בשם part2, למחוק את הקוד (להשאיר רק את הטסטים) ולממש בעצמו.
מה זה תכנות תגובתי?
תכנות תגובתי (Reactive Programming) כשמו כן הוא – מודל שמבוסס על תגובה לאירועים. בפועל זה מתבצע ע”י שימוש בזרמים תגובתיים (Reactive Streams), סוג של זרמים אסינכרוניים שמאפשרים לנו לעבוד בצורה מונחית אירועים. נגיב כאשר המידע הדרוש לנו מוכן ע”י הצהרה על קוד (callback) שיקרא ע”י המודל בתגובה לאירוע מסוים. שימו לב שניתן למדל כל פעולה בצורה זאת, כולל קריאת רשת ואפילו קליק בעכבר.
התכנות עצמו מתבצע בצורה פונקציונלית שמאפשרת כתיבת קוד הצהרתי, קוד יותר תמציתי ותיאורי ולכן יותר קל להבנה ולקידוד.
המודל מאפשר Non blocking IO (או בקיצור NIO) בצורה טבעית. בפעולת IO רגילה הנים (thread) תפוס (busy wait) בזמן שהוא מחכה למידע מהרשת. בפעולת NIO המצב שונה, אנחנו נעזרים ביכולות של מערכת ההפעלה ומספקים callback שמופעל כאשר יש מידע זמין לקריאה. הצורך במודל זה נובע מכך שמספר הנימים המקסימלי האפשרי חסום בכמות הזיכרון בעוד שמספר חיבורי הרשת הפעילים יכול להיות גבוה הרבה יותר. כך שמתאפשר לטפל בכמות גדולה הרבה יותר של פניות עם אותה החומרה.
המודל מאפשר לטפל באירוע בודד וגם בזרם אין סופי של אירועים (כגון קבלת מידע רצופה מרכיב הGPS). זרז לשימוש במודל הוא תמיכה בלחץ נגדי (backpressure), אפשרות ל’סמן’ לשרת מרוחק להאט את מהירות השליחה. שימושי למשל כאשר צריך לחכות למידע משרת נוסף איטי יותר לצורך הטיפול בבקשה וקיימת סכנה לחוסר במשאבים עקב ה’הפגזה’ של השרת המהיר (שאת המידע ממנו נצטרך לשמור בזיכרון עד שנוכל להחזיר את התשובה).
לכאורה אין כאן משהו חדש אז על מה כל הבאז? בעיקר על הקלות שזה מתבצע והעצמה שמקבלים. תכנות תגובתי מחבר את NIO עם עולם הזרמים והתכנות הפונקציונלי ומספק לנו ממשק (API) נוח ופרודוקטיבי.
המשך פיתוח האפליקציה מהחלק הראשון
קריאה לשירות חיצוני
כזכור, האפליקציה שבנינו בחלק הראשון מספקת מידע על אחסון של אתרים (ISP) וכרגע מחזירה מידע דמה סטטי. כעת, נבנה מחבר (connector/client) לאתר חיצוני (ip-api) שממנו נשאב את המידע עבור דומיין מסוים.
ראשית נרשום טסט:
import io.kotlintest.shouldBe
import io.kotlintest.specs.StringSpec
class ConnectorTests: StringSpec({
"ip-api returns correct hosting details" {
IpApiConnector().invoke("codejunkie.blog") shouldBe
HostingDetails(isp = "GoDaddy.com, LLC1", country = "United States")
}
})
נשתמש בספריית KotlinTest (הסבר בחלק הראשון) שמאפשרת מתן שם טסט אינפורמטיבי בשפה טבעית וטסט בצורת DSL. בקוטלין ויתרו על new – בשורה 7 אנחנו יוצרים מופע חדש של HostingDetails ומשווים אותו לתוצאה המוחזרת מinvoke ע”י שימוש במתודה shouldBe.
KotlinTest עושה שימוש נרחב ביכולות הרחבת קוד קיים של קוטלין ובעצם מוסיפה למתודה invoke (קוד שלנו) פונקציות נוספות כגון shouldBe (קוד של הספרייה). ניתן לרשום את הטסט גם ככה, בצורה שיותר מזכירה ג’אווה:
class ConnectorTests: StringSpec({
"ip-api return correct hosting details" {
IpApiConnector().invoke("codejunkie.blog").shouldBe(
HostingDetails(isp = "GoDaddy.com, LLC", country = "United States"))
}
})
ה’קסם’ שמאפשר את הDSL הנקי מתבצע ע”י הגדרת הפונקציה shouldBe כפונקציית infix, שמאפשרת (תחת מספר מגבלות) להגדיר פונקציה שמקבלת משתנה ללא סוגריים (במקרה שלנו את HostingDetails) ואפילו לוותר על הנקודה ה’מקשרת’ מהפונקציה invoke שאותה היא מרחיבה וכך מתאפשר התחביר הנקי בדוגמה הראשונה.
כעת יש לנו קוד שלא מתקמפל, נעמוד על כל אחת מהשגיאות בטסט ונעזר בIntellij (ע”י alt+enter) כדי ליצור את הקוד החסר (שלד בלבד כמובן). קיבלנו את זה:
class IpApiConnector {
fun invoke(domain: String): Any {
TODO("not implemented") //To change body of created functions use File | Settings | File Templates.
}
}
class HostingDetails(isp: String, country: String) {
}
לצערי Intellij עדין לא מאפשרת לבחור את שם הקובץ בו אנחנו רוצים למקם את המחלקות ויוצרת קובץ נפרד לכל מחלקה. מכיוון שבקוטלין אפשר למקם מספר מחלקות באותו קובץ אני בחרתי לקרוא לקובץ controllers ולמקם את שתי המחלקות בו. נריץ את הטסט ונגלה שהוא נכשל עם שגיאה ברורה – מצוין.
נמלא את המחלקה IpApiConnector בקוד הדרוש כדי להעביר את הטסט:
class IpApiConnector {
private val client = WebClient.create("http://ip-api.com/json/")
fun invoke(domain: String) = client.
get().
uri(domain).
retrieve().
bodyToMono(DomainDetails::class.java).
block()
}
יש כאן מספר דברים חדשים. ראשית, נשים לב שמדובר בתכנות פונקציונלי שדוגל בתכנות הצהרתי/תיאורי, כלומר קוד שמתאר `מה` אנחנו רוצים לעשות ולא `איך` זה מבוצע בפועל. נעבור על הקוד שורה שורה:
שורה 2- ניצור מופע של WebClient (כזכור ללא new), עם כתובת בסיס (base url) שמצביעה לשירות החיצוני שאליו נרצה לגשת.
WebClient היא מחלקה שנוספה בספרינג 5.0 כחלק מספריית הWebFlux של ספרינג. הספרייה מבוססת על Project Reactor (ספרייה לתכנות תגובתי) ומאפשרת הוצאת קריאות HTTP בצורה תגובתית. העבודה עם WebClient ועם הAPI של Project Reactor היא בFluent API, שמאפשר שרשור פעולות ע”י החזרת this מכל מתודה.
שורה 5- מצהירים על פעולת get – כלומר GET HTTP Method. עדיין לא נשלחת קריאה בפועל.
שורה 6- נעביר URI שיתחבר לכתובת הבסיס שהגדרנו בשורה 2, כך שיתקבל http://ip-api.com/json/$domain, שהוא הURL הדרוש לצורך קבלת מידע עבור הדומיין מip-api.
שורה 7- מסיימת את הבקשה (בפועל עדיין לא מתבצעת קריאה)
שורה 8- נצהיר על המרה של התשובה (response body) שתחזור מהקריאה לאובייקט מטיפוס DomainDetails, שתבוצע בפועל ע”י שימוש בספריית Jackson המוכרת לצורך המרת הJSON החוזר מהקריאה. אובייקט זה נעטף בMono שהוא האובייקט שחוזר בפועל בשורה שמונה.
Mono הוא publisher לזרם תגובתי (reactive stream), זהו אובייקט מרכזי מProject Reactor שעליו מבוסס WebFlux. כדי שתתבצע קריאה בפועל יש צורך בצרכן (subscriber) שימשוך נתונים מהזרם/Mono. אדגיש שוב, ללא צרכן לא תתבצע הקריאה לip-api. כלומר, עד לשלב זה (כולל) בעצם הצהרנו על pipeline לביצוע אבל לא התבצעה קריאה בפועל.
שורה 9- נבצע block, שיעצור את הנים הנוכחי עד שתחזור תוצאה. זה משהו שלא נרצה לעשות לעולם בתכנות תגובתי, מכיוון שזה סותר את כל הרעיון שמאפשר להגיב לאירוע ולקבל Non blocking IO… אנחנו עושים את זה כאן באופן זמני, כדי להקל על ההבנה. ע”י ביצוע block אנחנו בעצם מייצרים צרכן לזרם שיחכה עד שיהיו נתונים בזרם (כלומר תשובה משירות הREST של ip-api).
נריץ שוב את הטסט ונגלה שהוא עדין נכשל עם השגיאה הבאה:
java.lang.AssertionError: expected: blog.codejunkie.demo.controller.HostingDetails@530dbe64 but was: blog.codejunkie.demo.controller.HostingDetails@3a2b04a9 Expected :blog.codejunkie.demo.controller.HostingDetails@530dbe64 Actual :blog.codejunkie.demo.controller.HostingDetails@3a2b04a9
מניח שזו שגיאה די מוכרת למתכנתיי ג’אווה מנוסים – לא מימשנו equals בHostingDetails וההשוואה נכשלה. בקוטלין יש פתרון פשוט, שימוש במילה שמורה data לפני הגדרת המחלקה:
data class HostingDetails(val isp : String, val country : String)
ע”י שינוי פשוט זה שינינו את המחלקה למחלקת נתונים (data class) שמייצרת מימוש אוטומטי של equals, hashCode ואפילו toString. השימוש בval לפני הגדרת התכונות של המחלקה מסמן שלא ניתן לשנות ערכים אחרי ההצבה (שקול לfinal בג’אווה). נריץ את הטסט – עובר!
לסיכום, הקוד למחבר (connector) נראה כך (הוספנו גם אנוטציה של Component כדי שנוכל לחווט לcontroller בהמשך):
@Component
class IpApiConnector {
private val client = WebClient.create("http://ip-api.com/json/")
fun invoke(domain: String) = client.get().uri(domain).retrieve().
bodyToMono(HostingDetails::class.java).block()
}
data class HostingDetails(val isp : String, val country : String)
עדין יש בעיה בקוד – כזכור ביצענו block בקוד פרודקשיין! נתקן ע”י העברה של המתודה block מהקוד לטסט:
class IpApiConnector {
private val client = WebClient.create("http://ip-api.com/json/")
fun invoke(domain: String) = client.get().uri(domain).retrieve().bodyToMono(HostingDetails::class.java)
}
data class HostingDetails(val isp : String, val country : String)
class ConnectorTests: StringSpec({
"ip-api return correct hosting details" {
IpApiConnector().invoke("codejunkie.blog").block() shouldBe
HostingDetails(isp = "GoDaddy.com, LLC", country = "United States")
}
})
בשינוי קטן זה שלקח חצי דקה בעצם שינינו את הטיפוס החוזר מinvoke למונו (Mono). בטסט אנחנו מבצעים block על המונו כדי לקבל תשובה (קוד הפרודקשיין שיפעיל את המחבר לא יבצע block, נראה זאת בהמשך).
נריץ את הטסט ונבצע commit. למי שלא עבד בKotlin אני ממליץ לשכפל את הפרויקט בGitHub, לעבור לcommit ולהחזיר את הblock לקוד הפרודקשיין. עכשיו תעשו את אותו דבר בגא’ווה ותוכלו להעריך כמה זמן הtype inference של קוטלין יכול לחסוך לכם וכמה גמישות מתאפשרת.
חיווט המחבר (Connector)
כעת נרצה לחווט את המחבר (Connector) כך שיקרא על-ידי הController. ראשית, נזכיר שבשלב זה המימוש של הcontroller קבוע ונראה כך (בדיוק כמו ש’עזבנו’ אותו בחלק הראשון של הפוסט):
@GetMapping("/isp")
fun ispDetails() = mapOf(
"country" to "United States",
"isp" to "GoDaddy.com, LLC"
)
נשנה את הטסט האינטגרטיבי שהגדרנו בחלק הראשון:
"codejunkie.blog return the correct details" {
given {
on {
get("/isp?domain=codejunkie.blog") itHas {
statusCode(200)
body("country", equalTo("United States"))
body("isp", equalTo("GoDaddy.com, LLC"))
}
}
}
}
"google.com return the correct details" {
given {
on {
get("/isp?domain=google.com") itHas {
statusCode(200)
body("country", equalTo("United States"))
body("isp", equalTo("Google"))
}
}
}
}
הטסט משתמש בRestAssured שהכרנו בחלק הראשון. הוספנו פרמטר domain לבקשה (במקום הURI הקבוע “isp/” מחלק אחד) וטסט נוסף, כדי שנוכל לבדוק התנהגות שונה לdomains שונים. הטסט הראשון שולח את codejunkie.blog ומצפה לאותה תשובה כמו קודם (כלומר, טסט זה יעבור עם המימוש הנוכחי של הcontroller), בעוד שהטסט השני שולח את google.com ומצפה לתשובה שונה. נריץ את הטסט ונראה שהוא אכן עובר עבור codejunkie ונכשל כצפוי עבור google.com.
נעשה גם שינוי קטנטן בבדיקת קצה לקצה:
"isp details service passes sanity - DSL" {
given {
on {
get("/isp?domain=codejunkie.blog") itHas {
statusCode(200)
}
}
}
}
הוספנו את הפרמטר domain גם לטסט זה, מכיוון שאנחנו עומדים להוסיפו לcontroller בתור פרמטר חובה.
כדי לגרום לטסט לעבור עבור google.com נחליף את התשובה הסטטית בקריאה למחבר שלנו על מנת לקבל תשובה דינמית (שתהיה שונה עבור כל דומיין). קלי קלות בקוטלין:
@RestController
class IspController(val connector : IpApiConnector) {
@GetMapping("/isp")
fun ispDetails(@RequestParam() domain: String) = connector.invoke(domain)
}
בשורה 5 אנחנו קוראים למחבר ומחזירים ישירות את האובייקט שחוזר ממנו, זהו אובייקט מטיפוס Mono שכזכור מצריך צרכן כדי לפעול. קודם ‘יצרנו’ צרכן זה ע”י ביצוע block במחבר עצמו, כעת הצרכן יווצר ע”י ספרינג שבעצם יפעיל את המתודה subscribe של המחלקה Mono (אחת ההעמסות שלה) על המונו שחוזר ויעביר לה consumer מתאים שימיר את האובייקט לתשובה מתאימה (כלומר לJSON שיחזור ללקוח שקרא לcontroller). למען הסדר הטוב, כך נראית מתודת subscribe של Mono:
public abstract class Mono<T> implements Publisher<T> {
....
....
public final Disposable subscribe(Consumer<? super T> consumer) {
....
}
...
...
}
מתודה זאת מקבלת callback (מטיפוס consumer) שנקרא ע”י התשתית של Reactor כאשר קיימים נתונים בזרם התגובתי. ספרינג בעצם מספק את הקוד שיופעל כאשר קיימים נתונים בזרם, כלומר כאשר קיים אירוע (event) שיש להגיב אליו.
אציין שניתן להשתמש בתחביר יותר פונקציונלי עבור הcontroller (שנוסף בספרינג 5) ועובד יפה בקוטלין. במקרה זה, לדעתי הקוד יותר ברור במבנה ה’ישן’. למי שבכל זאת מתעניין יש דוגמה לתחביר זה בGithub.
נריץ את הטסט האינטגרטיבי, אחרי שנראה שעבר נעלה את האפליקציה ונריץ את בדיקת הקצה לקצה ונבצע commit נוסף.
תמיכה במספר שרתים באותה בקשה
כעת נרצה לאפשר למשתמש שלנו לבקש מידע על מספר דומיינים באותה הבקשה. נוסיף בדיקת קצה לקצה לקבלת מספר דומיינים בקריאת POST יחידה:
"isp details service passes sanity for multiple hosts as input" {
given {
jsonBody(mapOf("domains" to arrayOf("codejunkie.blog", "google.com")))
on {
post("/isp") itHas {
statusCode(200)
}
}
}
}
כאמור, אנחנו רוצים להעביר את הדומיינים בגוף הבקשה ע”י שימוש במתודת POST של HTTP. כלומר הטסט מצפה למשהו כזה:
curl -X POST \
http://localhost:8080/isp \
-d '{"domains" : ["codejunkie.blog","google.com"]}'
שימו לב כמה קל ליצור את המבנה הנ”ל ע”י שימוש בmapOf וarrayOf של קוטלין.
בבדיקה הנ”ל אנחנו רק בודקים שהתשובה חוזרת בהצלחה ולא בודקים את תוכן התשובה, כך אנו מקבלים בדיקת קצה לקצה בסיסית שלא נצטרך לעדכן בכל שינוי קטן בזמן הפיתוח (יתכן שבהמשך נרצה לעבות אותה מעט).
כדי לבדוק את גוף התשובה נוסיף בדיקה אינטגרטיבית שמולה נוכל לפתח בצורה יותר מהירה:
"codejunkie.com and google.com return the correct details" {
given {
jsonBody(mapOf("domains" to arrayOf("codejunkie.blog", "google.com")))
on {
post("/isp") itHas {
statusCode(200)
body("[0].country", CoreMatchers.equalTo("United States"))
body("[0].isp", CoreMatchers.equalTo("GoDaddy.com, LLC"))
body("[1].country", CoreMatchers.equalTo("United States"))
body("[1].isp", CoreMatchers.equalTo("Google"))
}
}
}
}
מאוד דומה לטסט הקודם, שורות 7-10 שנוספו מכסות את בדיקת תוכן התשובה. למה צריך גם טסט קצה לקצה וגם טסט אינטגרטיבי? ההבדל הוא שהטסט האינטגרטיבי מעלה את האפליקציה כחלק מהטסט, בעוד שהטסט קצה לקצה מניח שהאפליקציה כבר למעלה. זה אמנם הבדל קטן אבל מספק את הביטחון שהאפליקציה מחזירה תשובה כשהיא עולה עצמאית.
טסט הקצה לקצה יוכל לשמש בהמשך לבדיקת אספקטים נוספים כגון התקנה, יציבות וריצה בסביבות שונות (ע”י שינוי קטן לטסט כך שיקבל את המכונה שמולה יש לבדוק). לעומת זאת, היתרון בטסט האינטגרטיבי הוא פיתוח מהיר יותר מול טסט זה ואכן בחלק הבא נשנה את הטסט האינטגרטיבי כך שהקריאה לשירות החיצוני תתבצע מול ‘שרת כפיל’ (WireMock) מה שיאיץ את מהירות טסט זה ויגדיל את היציבות שלו (עקב ביטול התלות בשרת חיצוני ‘אמיתי’).
מי שרוצה ללמוד עוד על סוגי הטסטים השונים בהם נשתמש בבלוג מוזמן לעיין בהסבר בחלק הראשון.
נותר רק להעביר את הטסטים… נוסיף לcontrollers את הקוד הבא:
@PostMapping("/isp")
fun multipleDomainsDetails(@RequestBody() multipleHostsRequest: MultipleHostsRequest) =
Flux.concat(multipleDomainsRequest.domains.map(connector::invoke))
data class MultipleDomainsRequest(val domains: List<String>)
מה בעצם קורה כאן? אנחנו רוצים לקרוא למחבר (connector) עבור כל אחד מהדומיינים ובכך לקבל תשובה עבור כולם באותה הבקשה. נעשה זאת ע”י שימוש בפונקציית map שממפה (ממירה) את הדומיין למונו שחוזר מהמתודה invoke של המחבר (map מקבלת למבדה), כך שFlux.concat תקבל רשימה של Monos (שחזרו מconnector.invoke) ותפעיל אותם סדרתית. בהמשך נראה כיצד ניתן בשינוי פשוט למקבל את הקריאות.
map שקולה למתודה domains.stream().map בג’אווה רק בהרבה פחות קוד. כלומר, בג’אווה היינו עושים משהו כזה:
List<Mono> monos = multipleDomainsRequest.domains.
stream().
map(connector::invoke).
collect(Collectors.toList())
return Flux.concat(monos)
מי שלא מכיר תכנות פונקציונלי ועבודה עם streams בג’אווה מוזמן לקרוא כאן.
שינוי מבנה התשובה
בשלב זה אנחנו מחזירים את הבקשה בסדר המתאים לבקשה (כלומר, המידע עבור הדומיין הראשון יחזור ראשון וכן הלאה), זה מתבצע עקב השימוש בconcat שמבצע הפעלה סדרתית. בביצוע מקבילי יתכן וזה לא יהיה המצב. כמובן שנוכל למיין את התוצאה, אך אופציה עדיפה היא פשוט לציין את שמות הדומיינים בתשובה החוזרת, כך שנדע באופן מפורש לאיזה דומיין שייכת כל תשובה.
נשנה את הבדיקה האינטגרטיבית לצפות למפה (משם הדומיין למידע עבורו):
"codejunkie.com and google.com return the correct details" {
given {
jsonBody(mapOf("domains" to arrayOf("codejunkie.blog", "google.com")))
on {
post("/isp") itHas {
statusCode(200)
body("'codejunkie.blog'.country", equalTo("United States"))
body("'codejunkie.blog'.isp", equalTo("GoDaddy.com, LLC"))
body("'google.com'.country", equalTo("United States"))
body("'google.com'.isp", equalTo("Google"))
}
}
}
}
רק כדי להבהיר, זוהי התשובה שהטסט מצפה לה:
{
"codejunkie.blog": {
"isp": "GoDaddy.com, LLC",
"country": "United States"
},
"google.com": {
"isp": "Google",
"country": "United States"
}
}
נשנה את הקוד כדי להעביר את הטסט:
@PostMapping("/isp")
fun multipleDomainsDetails(@RequestBody() request: MultipleHostsRequest) =
Flux.concat(request.domains.map { domain ->
connector.invoke(domain).map { data -> mapOf(domain to data) }
}).reduce({ a, b -> a.plus(b) })
נעבור על הקוד:
שורה 3- מתחילים כמו קודם, request.domains.map ממירה את הdoamin למונו שחוזר מconnector.invoke.
שורה 4- ממירה את המונו למפה שנוצרת ע”י mapOf (לא להתבלבל עם map שממפה/ממירה מאובייקט אחד לאחר) שבה ערך אחד, כך שהמפתח הוא הדומיין והערך הוא המידע עבור דומיין זה כפי שיחזור מהמונו. לאחר הקריאה לconcat נקבל Flux שיכול להכיל מספר ערכים, כלומר מספר מפות.
שורה 5- נאחד את כל המפות (הרשימה שחזרה מconcat) למפה אחת (עטופה במונו) ע”י הפעלת פונקציית reduce על הFlux ושימוש בפונקציה plus שקוטלין מוסיפה לmap (מאחורי הקלעים יש פשוט שימוש בpullAll של map המוכר מג’אווה).
כדי להבין מה באמת יצרנו, נצטרך לעוד מספר הסברים. שיניתי את הקוד כך שנוכל לראות את הטיפוסים:

כלומר, אכן חוזר מונו. אך הטיפוסים מעט מטעים, מכיוון שניתן לחשוב שהמונו כבר מכיל את המפה מאותחלת כאשר הוא חוזר, כלומר שהקריאות כבר בוצעו לפני שהחזרנו את המונו מהפונקציה (כמו שהיה מתבצע ב’תכנות מסורתי’). אך כזכור, מונו (ו-Flux) לא ‘פועלים’ ללא צרכן (subscriber).
נעזר בdebugger כדי להבין מה קורה:
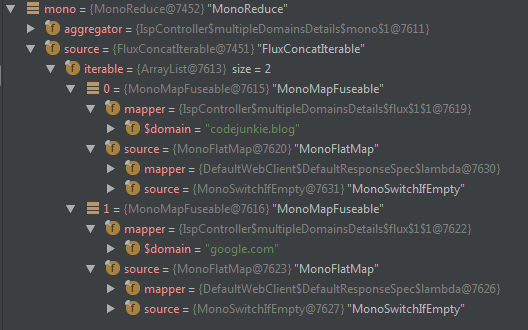
שמים לב לכל הלמבדות? יצרנו עץ של פעולות לביצוע, בעלים קיבלנו את הלמבדות (מDefaultWebClient) שיבצעו את הקריאה לאתר החיצוני בפועל, ומעליהן יש שורה של פעולות שיבצעו את ההמרות הדרושות לקבלת התשובה בפורמט המבוקש. ספרינג אחראי לצרוך את המונו ובעצם נקבל זרם תגובתי מקצה לקצה!
נריץ את הטסטים ונבצע commit אחרון לחלק זה של הפוסט. בחלק הבא נראה איך למקבל את הקריאות וכמובן איך לבדוק שהן באמת מתבצעות במקביל.
מתי נשתמש בתכנות תגובתי?
בחלק זה פיתחנו אפליקציה פשוטה וראינו את הממשק הנוח והפונקציונלי שמקובל בעולם התכנות התגובתי (ובפרט בProject Reactor ו-WebFlux). לא נחשפנו לכל החוזקות של הממשק, כמו למשל הוספה של delay או retries שמבוצעת בפשטות ע”י הוספת פעולה לקוד ההצהרתי. מצד שני, גם לא נחשפנו לכל הסיבוך הנלווה מהעבודה עם מונו עקב פשטות האפליקציה, אך זה בהחלט יסבך באפליקציה יותר מורכבת עם יותר שכבות ורכיבים.
היתרון כזכור הוא תמיכה במספר בקשות גדול הרבה יותר עם אותה חומרה, אך זה לא נחוץ ברוב האפליקציות. גם כאשר זה נחוץ בהחלט קיימות אלטרנטיבות שנצטרך לשקול, כגון קורוטינות (coroutines) שנתמכים בקוטלין ברמת השפה.
קורוטינות מספקות מעין נימים ‘רזים’, כך שניתן להריץ כמות רבה מאוד שלהן יחסית לנימים רגילים שצורכים הרבה יותר זיכרון. היתרון הוא שניתן לקבל אסינכרוניות וnon-blocking תוך שמירה על צורת תכנות אימפרטיבית (תכנות מפורש מסורתי) ללא שימוש במונו וצרכנים. ניתן אפילו לשלב בין תכנות תגובתי וקורוטינות…
לסיכום, מדובר בעוד כלי שטוב שיהיה בארגז הכלים שלנו. לדעתי, בהחלט כדאי לשקול להשתמש בו כאשר צריכים לבצע פניות מורכבות וארוכות למספר שרתים, כאשר צריכים throughput גבוה או תמיכה בbackpressure. ניתן גם לשלב בין קוד חוסם וקוד תגובתי במידת הצורך ע”י שימוש בscheduler מתאים, אבל זה כבר נושא לפוסט אחר 😉
קישורים לקריאה נוספת
The introduction to Reactive Programming you’ve been missing
Going Reactive with Spring, Coroutines and Kotlin Flow
Reactor – How to Combine Publishers (Flux/Mono)
Why you should learn Reactive Programming (Android)
מעולה. תודה!
Good read. Thank you!